MotionCtrl: A Unified and Flexible
Motion Controller
for Video Generation
Zhouxia Wang1,2,
Ziyang Yuan1,3,
Xintao Wang1,5✉,
Yaowei Li1,4,
Tianshui Chen6,
Menghan Xia5
Ping Luo2✉
Ying Shan1,5,
1ARC Lab, Tencent PCG,
2The University of Hong Kong,
3Tsinghua University,
4Peking University,
5Tencent AI Lab,
6Guangdong University of Technology
-
We propose MotionCtrl, a unified and flexible motion controller for video generation.
This
controller is designed to independently and effectively manage both camera and object
motions in the
generated videos.
-
MotionCtrl can be deployed on LVDM [1] / VideoCrafter1 [2] (an improved version over LVDM), AnimateDiff[3] and SVD[4]. The
results
of these deployments are showcased on this page.
Selected Results of MotionCtrl + SVD
-
Current version of MotionCtrl + SVD has the capability to guide an image-to-video generation model to create videos with
both basic and complex
camera motion, given a sequence of camera poses.
-
You are able to generate videos with our provided
Gradio Demo
and
[Source Code].
Selected Results of MotionCtrl + VideoCrafter
-
MotionCtrl has the capability to guide the video generation model in creating videos with
complex
camera motion, given a sequence of camera poses.
-
MotionCtrl can guide the video generation model to produce videos with specific object
motion,
provided object trajectories.
-
These results are generative with only one unified trained model.
Abstract
Motions in a video primarily consist of camera motion, induced by camera movement, and object motion,
resulting from
object movement. Accurate control of both camera and object motion is essential for video
generation.
However, existing works either mainly focus on one type of motion or do not clearly distinguish between
the two,
limiting their control capabilities and diversity. Therefore, this paper presents MotionCtrl, a unified
and flexible
motion controller for video generation designed to effectively and independently control camera and
object
motion. The
architecture and training strategy of MotionCtrl are carefully devised, taking into account the inherent
properties of
camera motion, object motion, and imperfect training data. Compared to previous methods, MotionCtrl
offers three main
advantages: 1) It effectively and independently controls camera motion and object motion, enabling more
fine-grained
motion control and facilitating flexible and diverse combinations of both types of motion. 2) Its motion
conditions are
determined by camera poses and trajectories, which are appearance-free and minimally impact the
appearance or shape of
objects in generated videos. 3) It is a relatively generalizable model that can adapt to a wide array of
camera poses
and trajectories once trained. Extensive qualitative and quantitative experiments have been conducted to
demonstrate the
superiority of MotionCtrl over existing methods.
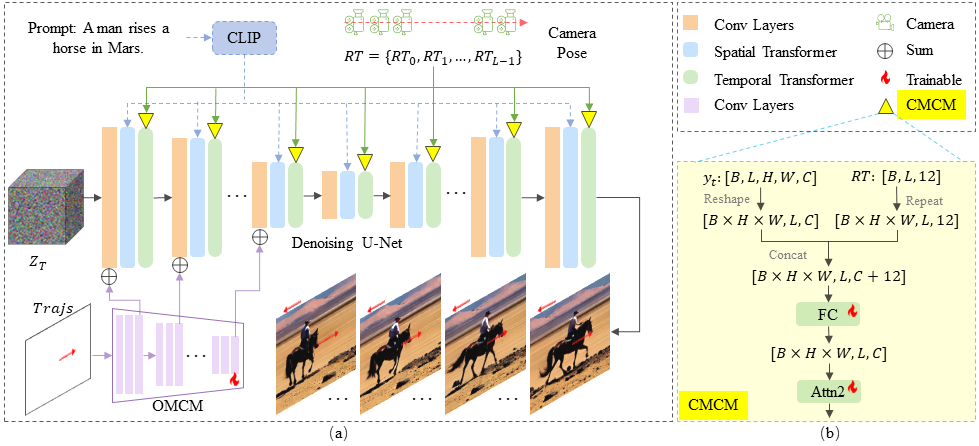
Methods
MotionCtrl extends the Denoising U-Net structure of LVDM with a Camera Motion Control Module (CMCM) and
an Object Motion
Control Module (OMCM). As illustrated in (b), the CMCM integrates camera pose sequences RT with
LVDM's
temporal
transformers by appending RT to the input of the second self-attention module and applying a
tailored
and lightweight
fully connected layer to extract the camera pose feature for subsequent processing. The OMCM utilizes
convolutional
layers and downsamplings to derive multi-scale features from Trajs, which are spatially
incorporated
into LVDM's
convolutional layers to direct object motion. Further given a text prompt, LVDM generates videos from
noise that
correspond to the prompt, with background and object movements reflecting the specified camera poses and
trajectories.
Results based on LVDM [1] / VideoCrafter1 [2]
Nothed that all the results, including the results of camera motion, object motion,
and combination of these two motions are attained with only one unified trained model.
(A) Camera Motion Control
(a) MotionCtrl produces videos with complex camera motion.
| Camera Motion |
Prompt |
Sample 1 |
Sample 2 |
Sample 3 |
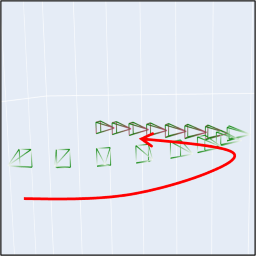
|
"A dog sitting on
the green grass."
|
|
|
|
|
|
"A cat lying on
the floor."
|
|
|
|
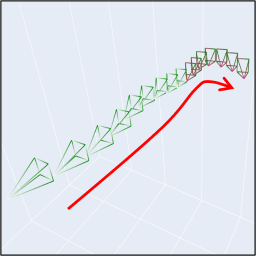
|
"A castle in
the forest."
|
|
|
|
|
|
"A temple on
the mountains."
|
|
|
|
(b) MotionCtrl produces videos with 8 basic camera motions.
| Pan Up |
Pan Down |
Pan Left |
Pan Right |
|
|
|
|
|
| Zoom In |
Zoom Out |
Anti-Clockwise |
Clockwise |
|
|
|
|
|
Prompt: "A landscape with mountains and lakes at sunrise."
(c) MotionCtrl can fine-grainedly adjust the camera motion of the generated video.
| 0.2x Speed |
0.4x Speed |
1.0x Speed |
2.0x Speed |
|
|
|
|
|
Zoom In
Zoom Out
Prompt: "Rocky coastline with crashing waves."
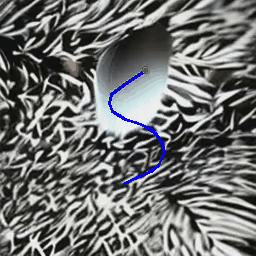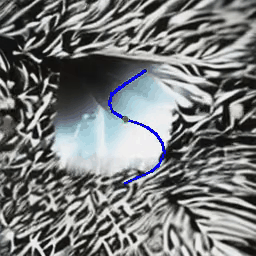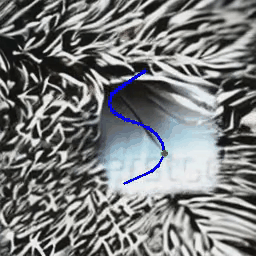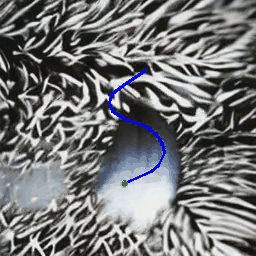
(B) Object Motion Control
MotionCtrl produces videos with specific object motion,
given a single or multiple object trajectories.
| Trajectory(ies) |
Prompt |
Sample 1 |
Sample 2 |
Sample 3 |
|
|
"Wind chime" |
|
|
|
|
|
"Sunflower" |
|
|
|
|
|
"Paper plane" |
|
|
|
|
|
"Fallen leaf" |
|
|
|
|
|
"Two zebras" |
|
|
|
|
|
"Two cats" |
|
|
|
(C) Camera + Object Motion Control
MotionCtrl can simultaneously control the camera and object motion.
| Camera Motion |
Object Motion |
Prompt |
Resutls |
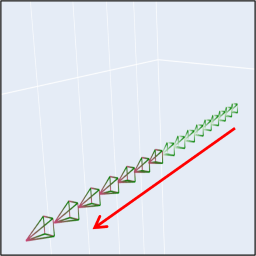
|
|
"The rose is swaying
in the wind."
|
|
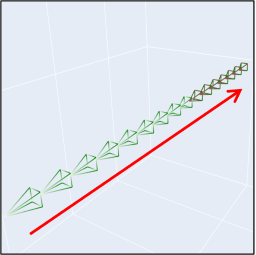
|
|
"A horse running
on the road."
|
|
(D) Comparisons with VideoComposer [5]
MotionCtrl generates videos with camera or object motion well aligned with the
reference videos or given trajectories, while maintaining a natural appearance.
.
|
Camera Motion
Provided Reference Video
|
Prompt |
VideoComposer [5] |
MotionCtrl |
|
|
"Eiffel Tower in Paris." |
|
|
|
|
"A human robot
standing on Mars."
|
|
|
| Object Motion |
Prompt |
VideoComposer [5] |
MotionCtrl |
|
|
"A girl is skiing." |
|
|
|
|
"A feather floating
in the air."
|
|
|
Results based on AnimateDiff[3]
Nothed that all the results, including the results of camera motion and object motion,
are attained with only one unified trained model.
(A) Camera Motion Control
(a) There are results with 8 basic camera motions.
| Pan Up |
Pan Down |
Pan Left |
Pan Right |

|

|

|

|
| Zoom In |
Zoom Out |
Anti-Clockwise |
Clockwise |

|

|

|

|
Prompt: "A teddy bear at the supermarket."
(b) There are results of zoom in and zoom out with different speeds.
| 1.0x Speed |
2.0x Speed |
3.0x Speed |
5.0x Speed |

|

|

|

|
Zoom In
Zoom Out
Prompt: "A castle on the mountains."
(c) There are results with complex camera motions.
| Camera Motion |
Sample |
Camera Motion |
Sample |
Camera Motion |
Sample |
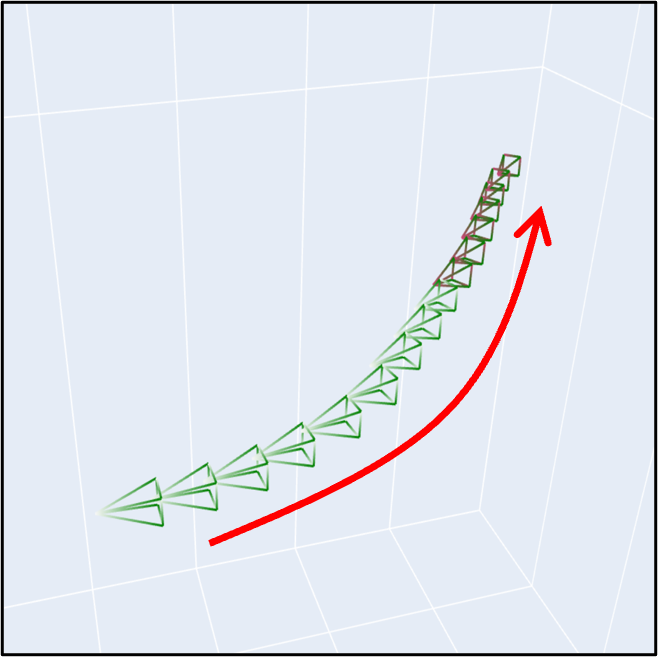
|

|
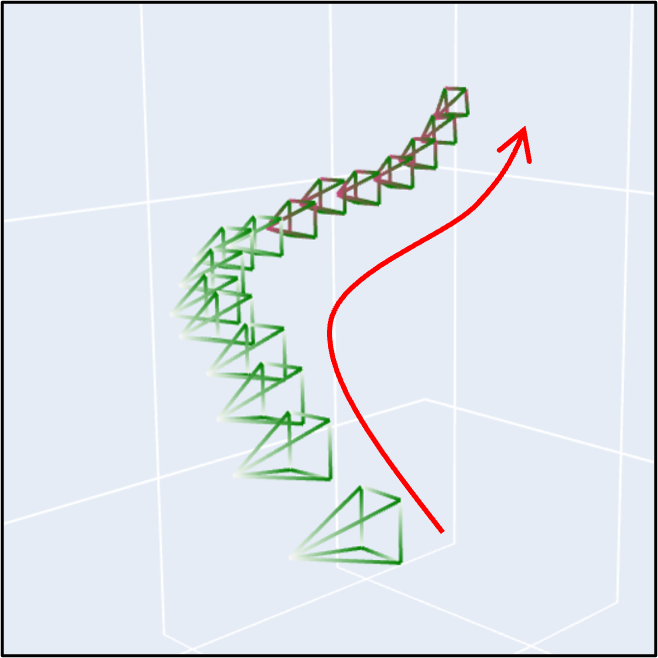
|

|
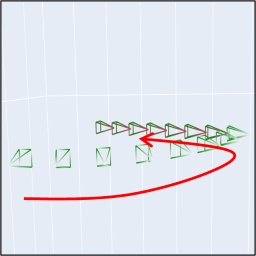
|

|
Prompt: "A girl."
(B) Object Motion Control
There are results with specific object motion.
References
[1] Yingqing He, Tianyu Yang, Yong Zhang, Ying Shan, and Qifeng Chen. Latent video diffusion models for
high-fidelity long video generation. arXiv preprint arXiv:2211.13221, 2023.
[2] Chen H, Xia M, He Y, et al. Videocrafter1: Open diffusion models for high-quality video generation[J].
arXiv
preprint
arXiv:2310.19512, 2023.
[3] Yuwei Guo, Ceyuan Yang, Anyi Rao, Yaohui Wang, Yu Qiao, Dahua Lin, and Bo Dai. Animatediff: Animate your
personalized text-to-image diffusion models without specific tuning. arXiv preprint arXiv:2307.04725, 2023.
[4] Blattmann A, Dockhorn T, Kulal S, et al. Stable Video Diffusion: Scaling Latent Video Diffusion Models
to Large
Datasets[J]. arXiv preprint arXiv:2311.15127, 2023.
[5] Xiang Wang, Hangjie Yuan, Shiwei Zhang, Dayou Chen, Jiuniu Wang, Yingya Zhang, Yujun Shen, Deli Zhao,
and
Jingren Zhou. Videocomposer: Compositional video synthesis with motion controllability. arXiv preprint
arXiv:2306.02018, 2023.
BibTex
@article{wang2024motionctrl,
title={MotionCtrl: A Unified and Flexible Motion Controller for Video Generation},
author={Wang, Zhouxia and Yuan, Ziyang and Wang, Xintao and Li, Yaowei and Chen, Tianshui and Xia, Menghan and Luo, Ping and Shan,
Ying},
booktitle={ACM SIGGRAPH 2024 Conference Papers},
year={2023}
}








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}